Perform Bayes optimization based on Gauss process using PHYSBO
Download script from bayes_gp_plain.py
Related files:
bayes_gp_plain.zip
import sys
import os
import re
import numpy as np
from numpy import sqrt
import physbo
import matplotlib.pyplot as plt
import pandas as pd
#===================================================================================
"""
Perform Bayes optimization based on Gauss process using PHYSBO
"""
#===================================================================================
#===================================================================================
usage_str = '''
f"(i) usage: python {sys.argv[0]} infile max_num_probes num_rand_basis score_mode interval"
f" max_num_probes: Use a number to reach convergence"
f" num_rand_basis: Use a large number so as to reproduce training data"
f" score_mode : [EI|PI|TS]"
f" interval : # of cycle to update hyper parameters"
f" ex: python {sys.argv[0]} {cparams.infile} {cparams.max_num_probes} {cparams.num_rand_basis} {cparams.score_mode} {cparams.interval}"
'''[1:-1]
#===================================================================================
#===================================================================================
# Basic functions / classes
#===================================================================================
def pint(s, strict = True, defval = 0):
try:
return int(s)
except:
return defval
def pfloat(s, strict = True, defval = 0.0):
try:
return float(s)
except:
return defval
def pintfloat(s, strict = True, defval = 0.0):
try:
return int(s)
except:
pass
try:
return float(s)
except:
return defval
def getarg(position, defval = None):
try:
return sys.argv[position]
except:
return defval
def getfloatarg(position, defval = None):
return pfloat(getarg(position, defval))
def getintarg(position, defval = None):
return pint(getarg(position, defval))
class tkObject:
def get(self, key, defval = None):
return self.__dict__.get(key, defval)
def set_attribute(self, key, val):
self.__dict__[key] = val
def update(self, **args):
self.__dict__.update(args)
def printinf(self, app):
print("Parameters:")
for key in self.__dict__.keys():
print(f" {key}: {self.__dict__[key]}")
class tkParams(tkObject):
def __init__(self, parameter_file = None, **args):
super(tkObject, self).__init__(**args)
self._argv = sys.argv
self.update(**args)
def printinf(self, app):
print("Parameters:")
for key in self.__dict__.keys():
print(f" {key}: {self.__dict__[key]}")
class tkApplication(tkObject):
def __init__(self, _globals = None, locals = None, **args):
super().__init__()
self.params = tkParams()
self.argv = sys.argv
self.script_path = sys.argv[0]
self.usage_str = None
self.globals = globals
self.locals = locals
self.update(**args)
def get_argv(self):
return sys.argv, len(sys.argv)
def get_params(self):
if self.get('cparams', None) is None:
self.cparams = tkParams()
return self.cparams
def print(self, *args, **kwargs):
print(*args, **kwargs)
#===================================================================================
# Other functions
#===================================================================================
def usage(app):
cparams = app.get_params()
for s in usage_str.split('\n'):
cmd = 'app.print({})'.format(s.rstrip())
eval(cmd)
def terminate(app, message = None, usage = None):
if message is not None:
app.print("")
app.print(message)
if usage:
app.print("")
usage(app)
app.print("")
exit()
def initialize():
#================================
# Global variables
#================================
app = tkApplication(usage_str = usage_str)
argv, narg = app.get_argv()
cparams = app.get_params()
cparams.debug = 0
cparams.print_level = 0
cparams.infile = 'data_simple.xlsx'
# cparams.infile = 'data_simple.csv'
cparams.num_search_each = 1
cparams.max_num_probes = 1
cparams.num_rand_basis = 200 # -1 for non-approximated
cparams.score_mode = 'EI'
cparams.interval = 0
return app, cparams
def update_vars(app, cparams):
argv, narg = app.get_argv()
# if narg <= 1:
# app.terminate(usage = usage)
cparams.infile = getarg (1, cparams.infile)
cparams.max_num_probes = getintarg(2, cparams.max_num_probes)
cparams.num_rand_basis = getintarg(3, cparams.num_rand_basis)
cparams.score_mode = getarg (4, cparams.score_mode)
cparams.interval = getintarg(5, cparams.interval)
header, ext = os.path.splitext(cparams.infile)
filebody = os.path.basename(header)
cparams.outfile = filebody + f'-predict.xlsx'
#====================================================
# Graph parameters
#====================================================
cparams.figsize = (12, 8)
cparams.fontsize = 16
cparams.legend_fontsize = 8
def load_data(app, cparams):
print("")
print(f"Read data from [{cparams.infile}]")
try:
if '.xlsx' in cparams.infile:
df = pd.read_excel(cparams.infile, engine = 'openpyxl')
else:
df = pd.read_csv(cparams.infile)
except:
terminate(app, f"Error in load_data(): Can not read [{cparams.infile}]", usage = usage)
columns = df.columns.to_list()
index = df.index.to_list()
ncol = len(columns)
ndata = len(df.index)
target = columns[0]
target_mode = 'max'
target_value = 0
descriptors = []
# ヘッダーの制御コードにより、記述子と目的関数、変換モードを抽出
for s in columns:
# 数値最適化
if re.match(r'=([+-\.\deE]+):', s, flags = re.IGNORECASE):
target = s
match = re.match(r'=([+-\.\deE]+):', s, flags = re.IGNORECASE)
target_mode = 'value'
target_value = pfloat(match.groups()[0])
# 最大化
elif re.match(r'max:', s, flags = re.IGNORECASE):
target = s
target_mode = 'max'
# 最小化
elif re.match(r'min:', s, flags = re.IGNORECASE):
target = s
target_mode = 'min'
# 記述子、目的関数から除外
elif re.match(r'\-', s):
pass
else:
# 記述子に追加
descriptors.append(s)
# 記述子に目的関数と同じ列が入っている場合、削除
try:
descriptors.remove(target)
except:
pass
print(" columns :", columns)
print(" target :", target)
print(" descriptors:", descriptors)
if target_mode == 'value':
print(f" target_mode: {target_mode} value={target_value}")
else:
print(" target_mode:", target_mode)
# exit()
t_all = df[target]
x_all = df[descriptors]
# target functionがnanでないデータを学習データとして抽出
df2 = df.dropna(how = 'any')
idx_train = df2.index.to_numpy()
# df2 = df2.reset_index()
t_train = df2[target]
x_train = df2[descriptors]
# descriptorにnanがあるデータを削除
drop_idx_all = []
drop_idx_train = []
for idx in index:
if x_all.iloc[idx].isnull().any():
drop_idx_all.append(idx)
if idx in idx_train:
drop_idx_train.append(idx)
t_all = t_all.drop(index = drop_idx_all, axis = 0)
x_all = x_all.drop(index = drop_idx_all, axis = 0)
t_train = t_train.drop(index = drop_idx_train, axis = 0)
x_train = x_train.drop(index = drop_idx_train, axis = 0)
t_all = t_all.to_numpy()
x_all = x_all.to_numpy()
t_train = t_train.to_numpy()
x_train = x_train.to_numpy()
# ヘッダーの制御コードによって目的関数を変換。もとの目的関数は t_train_org に保存
t_train_org = t_train
if target_mode == 'min':
t_train = -t_train
elif target_mode == 'value':
t_train = -(t_train - target_value)**2
return target, descriptors, target_mode, target_value, idx_train, x_train, t_train_org, t_train, x_all, t_all
def execute(app, cparams, wait_by_input = True):
argv, narg = app.get_argv()
physbo_url = "https://www.pasums.issp.u-tokyo.ac.jp/physbo/"
citation_url = "https://issp-center-dev.github.io/PHYSBO/manual/master/en/introduction.html"
app.print("")
app.print( "====================================================================================")
app.print(f" {argv[0]}: Perform Bayes optimization based on Gauss process ")
app.print(f" Requires PHYSBO: {physbo_url}")
app.print(f" Citation: {citation_url}")
app.print( "====================================================================================")
cparams.printinf(app)
target, descriptors, target_mode, target_value, idx_train, X_train, t_train_org, t_train, X_all, t_all \
= load_data(app, cparams)
ndata = len(t_all)
n_traindata = len(idx_train)
app.print("")
app.print(f"# of training data: {n_traindata}")
app.print(f"# of all data: {len(t_all)}")
# app.print("X_train=")
# app.print(X_train)
# app.print("t_train=")
# app.print(t_train)
# app.print("X_all=")
# app.print(X_all)
# app.print("t_all=")
# app.print(t_all)
# policy のセット
app.print("")
app.print("Make policy:")
app.print(" Training data indexes:")
app.print(idx_train)
app.print(" descriptors from X_train:")
app.print(X_train)
app.print(" descriptors from X_all:")
app.print(X_all[idx_train])
app.print(" target values:")
app.print(t_train)
# 2021-05-23 物性研CCMS講習会 本山裕一
# 「ベイズ最適化パッケージ PHYSBOの使い方」 physbo_usage.pdf
policy = physbo.search.discrete.policy(test_X = X_all, initial_data = (idx_train, t_train))
# シード値のセット
# policy.set_seed(0)
# bayes_searchは、simulator = Noneでは actions が返り、simulatorに関数を渡すと Hisotry object が返ってくる
app.print("")
app.print("Start Bayes search:")
actions = policy.bayes_search(max_num_probes = cparams.max_num_probes, simulator = None,
score = cparams.score_mode, interval = cparams.interval, num_rand_basis = cparams.num_rand_basis)
app.print("")
app.print("Bayse search:")
app.print("show_search_results")
physbo.search.utility.show_search_results(policy.history, 10)
# Hisotry objectの取得
res = policy.export_history()
best_fx, best_action = res.export_all_sequence_best_fx()
bayes_x = res.chosen_actions
x_bayes = X_all[bayes_x]
y_bayes = res.fx
# 獲得関数
score = policy.get_score(mode = "EI", xs = X_all)
# 回帰。事後分布の平均値、分散
mean = policy.get_post_fmean(X_all)
var = policy.get_post_fcov(X_all)
std = np.sqrt(var)
mean_m_sigma = mean - std
mean_p_sigma = mean + std
# Best action
app.print("Best action history")
app.print(" best_action indexes:", best_action)
app.print("Snapshots of best actions and fx:")
x_prev = None
x_besthistory = []
y_besthistory = []
for idx in best_action:
x = X_all[idx]
if x_prev is not None:
r = np.linalg.norm(x - x_prev)
# print("r=", r, x, x_prev)
if r < 1.0e-5:
continue
y = policy.get_post_fmean(x)
x_besthistory.append(x)
y_besthistory.append(y)
x_prev = x
# print(f" (", x, f") ", y)
app.print(" Best score history: ", x_besthistory, y_besthistory)
X_best = X_all[int(best_action[-1])]
Y_best = policy.get_post_fmean(X_best)
#print("score=", score)
idx_best = np.argmax(score)
app.print(" Best candidate :", idx_best, X_all[idx_best], mean[idx_best])
# app.print(" Best candidate from hisotry:", int(best_action[-1]), X_best, Y_best)
print("")
print(f"Save predictions to [{cparams.outfile}]")
print("X_all.T=")
print(X_all.T)
zlist = zip(*X_all.T, t_all, mean, mean_m_sigma, mean_p_sigma)
df = pd.DataFrame(list(zlist),
columns = [*descriptors, target, 'mean', 'mean-std', 'mean+std'])
df.to_excel(cparams.outfile)
#=====================================================
# plot
#=====================================================
fig = plt.figure(figsize = cparams.figsize)
# ax1 = fig.add_subplot(1, 1, 1)
ax3 = fig.add_subplot(1, 1, 1)
ax3b = ax3.twinx()
"""
ax1.plot(best_fx, label = 'best action', color = 'black')
ax1.set_xlabel("sequence", fontsize = cparams.fontsize)
ax1.set_ylabel("value", fontsize = cparams.fontsize)
ax1.tick_params(labelsize = cparams.fontsize)
ax1.legend(fontsize = cparams.legend_fontsize, loc = 'best')
"""
x = range(len(X_all))
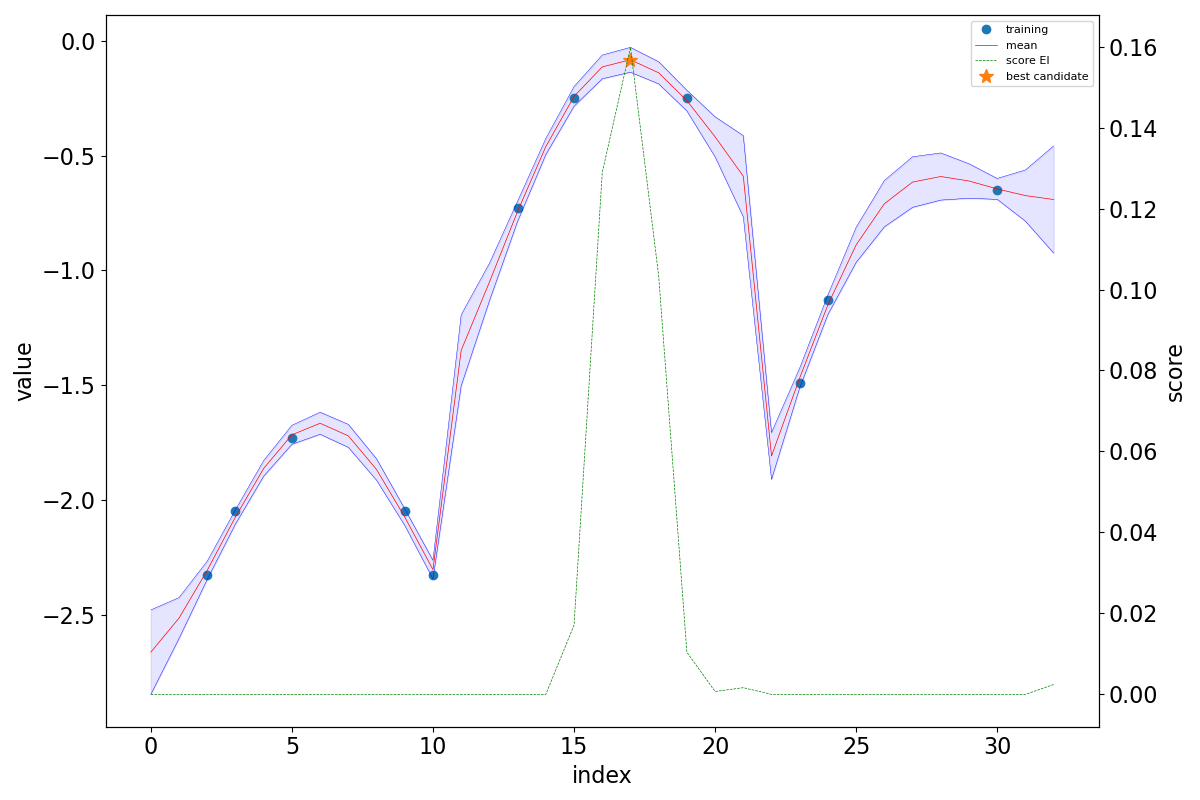
ins1 = ax3.plot(idx_train, t_train, label = 'training', linestyle = '', marker = 'o')
ins3 = ax3.plot(x, mean, label = 'mean', color = 'black', linewidth = 0.5)
# ax3.plot(x, mean + std, color = 'blue', linewidth = 0.3)
# ax3.plot(x, mean - std, color = 'blue', linewidth = 0.3)
ins6 = ax3b.plot(x, score, label = f'score {cparams.score_mode}', color = 'red', linestyle = 'dashed', linewidth = 0.5)
ins7 = ax3.plot(idx_best, mean[idx_best], label = 'best candidate', linestyle = '', marker = '*', markersize = 10.0)
ax3.fill_between(x, mean_m_sigma, mean_p_sigma, color='b', alpha=.1)
if target_mode == 'value':
ax3.plot(ax3.get_xlim(), [0.0, 0.0], linestyle = 'dashed', linewidth = 0.5, color = 'red')
ax3.minorticks_on()
# ax3.set_xticklabels(range(ndata))
ax3.grid(which = "major", axis = "x", color = "green", alpha = 0.5, linestyle = '--', linewidth = 0.5)
ax3.grid(which = "minor", axis = "x", color = "green", alpha = 0.5, linestyle = '--', linewidth = 0.1)
ax3.set_xlabel( "index", fontsize = cparams.fontsize)
ax3.set_ylabel( "value", fontsize = cparams.fontsize)
ax3b.set_ylabel(f"score {cparams.score_mode}", fontsize = cparams.fontsize)
# ax3b.set_yscale('log')
ax3.tick_params( labelsize = cparams.fontsize)
ax3b.tick_params(labelsize = cparams.fontsize)
ins = ins1 + ins3 + ins6 + ins7
ax3.legend(ins, [l.get_label() for l in ins], fontsize = cparams.legend_fontsize, loc = 'best')
# ax1.set_ylim(ax3.get_ylim())
plt.tight_layout()
plt.pause(0.1)
res.save('search_result.npz')
def find_nearest_data(x, y, xlist, ylist):
minr2 = 1.0e300
ihit = None
for i in range(len(xlist)):
xi = xlist[i]
yi = ylist[i]
r2 = (x - xi)**2 + (y - yi)**2
# print("i=", i, x, y, xi, yi, r2, end = '')
if minr2 > r2:
minr2 = r2
ihit = i
# print(" => ", minr2, ihit)
return ihit, minr2
def onclick(event):
# print("click", event.inaxes, ax1, ax3, ax3b)
if event.inaxes != ax3 and event.inaxes != ax3b:
return
xe, ye = event.xdata, event.ydata
# inaxiesがaxis3bの場合、yeをaxis3の値に変換
if event.inaxes == ax3b:
ylim1 = ax3.get_ylim()
ylim2 = ax3b.get_ylim()
ye = ylim1[0] + (ylim1[1] - ylim1[0]) / (ylim2[1] - ylim2[0]) * (ye - ylim2[0])
idx, r2 = find_nearest_data(xe, ye, range(ndata), mean)
# idx, r2 = find_nearest_data(xe, ye, x, mean)
app.print("")
app.print(f"clicked at idx = {idx} / line {idx+2}: descriptors =", X_all[idx], " given target value =", t_all[idx])
app.print(f" predicted target value = {mean[idx]} +- {std[idx]}")
fig.canvas.mpl_connect("button_press_event", onclick)
# fig.canvas.mpl_connect("motion_notify_event", hover)
print("")
usage(app)
if wait_by_input:
print("")
print("Press ENTER to terminate")
input()
if __name__ == "__main__":
app, cparams = initialize()
update_vars(app, cparams)
execute(app, cparams)
terminate(app, "", usage = None)